Imputing the Time-Series Using Python

Time series are an important form of indexed data found in stocks data, climate datasets, and many other time-dependent data forms. Due to its time-dependency, time series are subject to have missing points due to problems in reading or recording the data.
To apply machine learning models effectively, the time series has to be continuous, as most of the ML models are not designed to deal with missing values. Hence, the rows with missing data should be either dropped or filled with appropriate values.
In time-independent data (non-time-series), a common practice is to fill the gaps with the mean or median value of the field. However, this is not applicable in the time series. To understand the reason, let’s consider a temperature dataset. The temperature value of February is very far from its value in July. This is also applicable to sales dataset that has some seasons with high sales and others with low or regular sales. So the imputation method should be dependent on time.
To prove this assumption, let’s take an example and solve it in python.
Loading and preparing the dataset
Import the required libraries, and read the data
# Import the required libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# Import a scoring metric to compare methods
from sklearn.metrics import r2_score%matplotlib inline
# the data path#To View the data go here:
#https://github.com/drnesr/WaterConsumption/blob/master/data/SampleData.csv"
# To load the raw data:remote_path = "https://raw.githubusercontent.com/drnesr/WaterConsumption/master/data/SampleData.csv"
df=pd.read_csv(remote_path)
df.head()

The dataset contains three columns, Date,the date in dd-mm-yyyy format; reference the temperature column with no missing data for reference; and target the temperature column with random missing points.
The first step is to set the index of the dataframe to be the Date column
# Converting the column to DateTime format
df.Date = pd.to_datetime(df.Date, format='%d-%m-%Y')
df = df.set_index('Date')
df.head()
For charting purposes, we will add a column that contains the missing values only.
df = df.assign(missing= np.nan)
df.missing[df.target.isna()] = df.reference
df.info()DatetimeIndex: 96 entries, 2010-01-15 to 2017-12-15
Data columns (total 3 columns):
reference 96 non-null float64
target 75 non-null float64
missing 21 non-null float64
dtypes: float64(3)
Notice that we have 21 missing points out of 96 total points.
Have a look at the data df.plot(style=['k--', 'bo-', 'r*'], figsize=(20, 10));
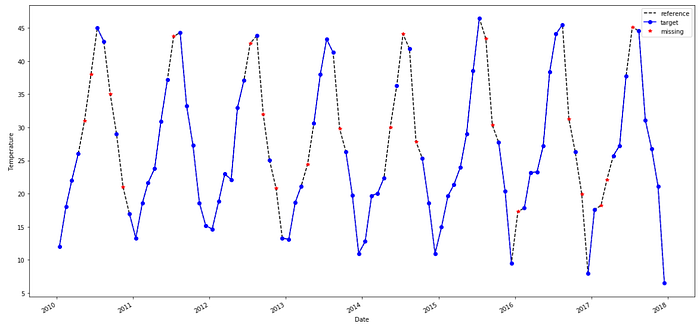
Trying to impute using the mean/median values.
I will create a column for each tested method to compare the values later.
# Filling using mean or median# Creating a column in the dataframe
# instead of : df['NewCol']=0, we use
# df = df.assign(NewCol=default_value)
# to avoid pandas warning.df = df.assign(FillMean=df.target.fillna(df.target.mean()))
df = df.assign(FillMedian=df.target.fillna(df.target.median()))
Trying to impute using the rolling average.
# imputing using the rolling average
df = df.assign(RollingMean=df.target.fillna(df.target.rolling(24,min_periods=1,).mean()))
# imputing using the rolling median
df = df.assign(RollingMedian=df.target.fillna(df.target.rolling(24,min_periods=1,).median()))# imputing using the medianImputing using interpolation with different methods
df = df.assign(InterpolateLinear=df.target.interpolate(method='linear'))
df = df.assign(InterpolateTime=df.target.interpolate(method='time'))
df = df.assign(InterpolateQuadratic=df.target.interpolate(method='quadratic'))
df = df.assign(InterpolateCubic=df.target.interpolate(method='cubic'))
df = df.assign(InterpolateSLinear=df.target.interpolate(method='slinear'))
df = df.assign(InterpolateAkima=df.target.interpolate(method='akima'))
df = df.assign(InterpolatePoly5=df.target.interpolate(method='polynomial', order=5))
df = df.assign(InterpolatePoly7=df.target.interpolate(method='polynomial', order=7))
df = df.assign(InterpolateSpline3=df.target.interpolate(method='spline', order=3))
df = df.assign(InterpolateSpline4=df.target.interpolate(method='spline', order=4))
df = df.assign(InterpolateSpline5=df.target.interpolate(method='spline', order=5))Scoring the results and see which is better
results = [(method, r2_score(df.reference, df[method])) for method in list(df)[3:]]
results_df = pd.DataFrame(np.array(results), columns=['Method', 'R_squared'])
results_df.sort_values(by='R_squared', ascending=False)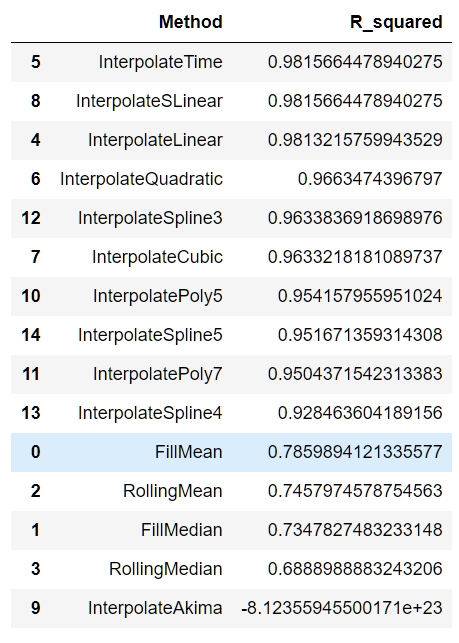
The result shows that the 'time' method as well as the 'slinear' method produces the closest values to the original values, while the rolling mean and median produces very low values of r^2.
To plot the data after imputation.
final_df= df[['reference', 'target', 'missing', 'InterpolateTime' ]]
final_df.plot(style=['b-.', 'ko', 'r.', 'rx-'], figsize=(20,10));
plt.ylabel('Temperature');
plt.legend(loc='upper center', bbox_to_anchor=(0.5, 1.05),
fancybox=True, shadow=True, ncol=5, prop={'size': 14} );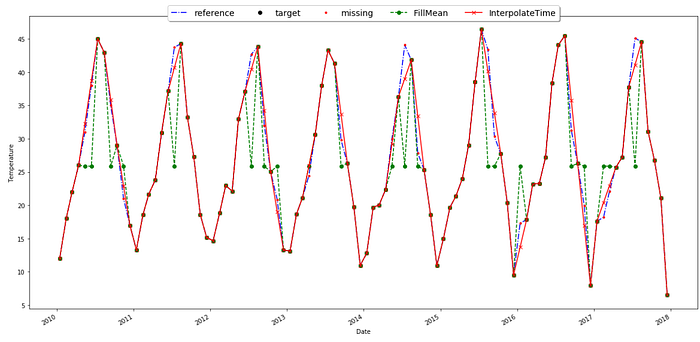
Some limitations
- For the
timeinterpolation to succeed, the dataframe must have the index in Date format with intervals of 1 day or more (daily, monthly, …); however, it will not work for time-based data, like hourly data. - if it is important to use a different index for the dataframe, use
reset_index().set_index('Date'), do the interpolation, and then apply thereset_index().set_index('DesiredIndex'). - If the data contains another dividing column, like the type of merchandise, and we are imputing sales, then the imputation should be for each merchandise separately.
Conclusions
It is important to keep the date in mind while imputing time-series, make the date as the dataset index, then use pandas interpolation with the time method.
Application on a real project
This time series imputation method was used to analyze real data in the study described in this post.
References
- Missing values in Time Series in python. A stack overflow article.
- How to Resample and Interpolate Your Time Series Data With Python.
- A git hub copy of the jupyter notebook
—
Note: This is my first story at Medium. I appreciate your valuable feedback and encouragement.